How to audit a robots.txt file for crawling issues
A robots.txt file is a text file that contains instructions for web crawlers about which pages or files the robot should access or ignore while crawling a website.
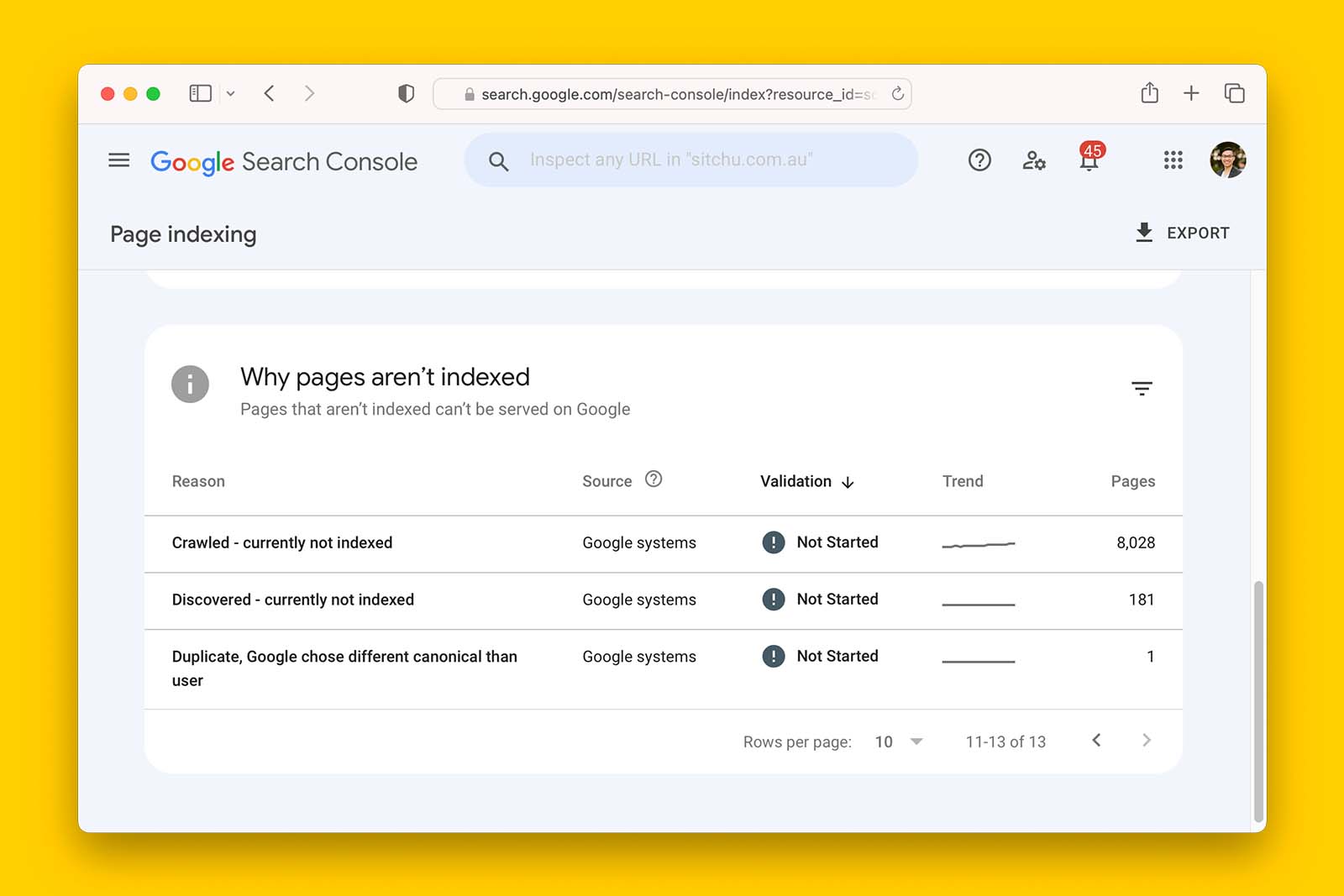
The robots.txt file matters because URLs that cannot be crawled by Googlebot cannot be found on Google search.
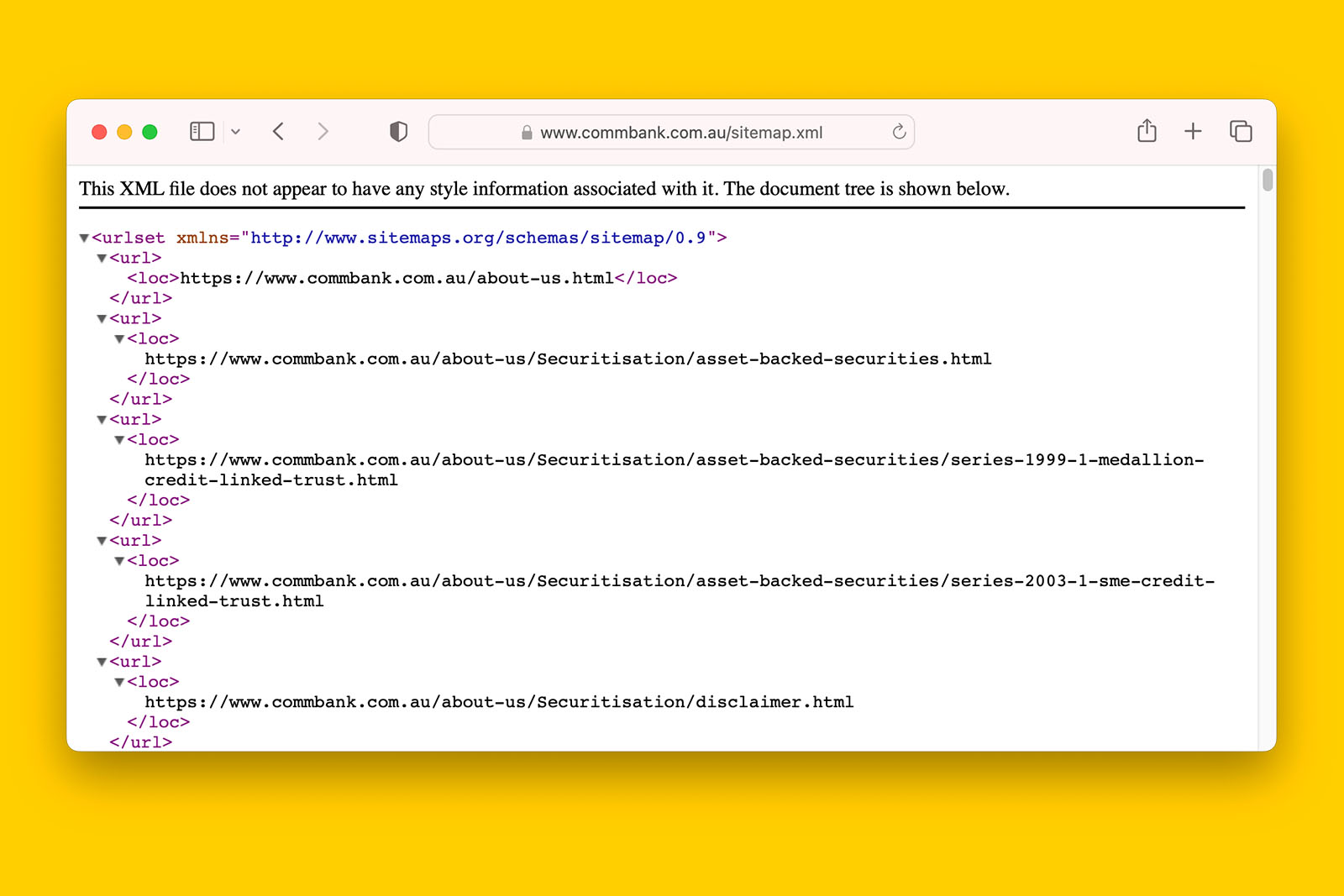
They can look like this:
User-agent: Swiftbot
Allow: /latest/lpi-refunds.html
Allow: /latest/loan-repayment-cover-refund.html
Allow: /latest/loan-protection-insurance-refund.html
# /robots.txt file for https://www.commbank.com.au/
User-agent: *
Disallow: /references/
Disallow: /merchants/
Disallow: /mobile/
#Blog
Disallow: /blog.feed
#PDFs
Disallow: /commbank/assets/about/careers/B481-Assessment-Centre-Flyer.pdf
Sitemap: https://www.commbank.com.au/sitemap.xml
Sitemap: https://www.commbank.com.au/content/dam/commbank/root/articles-sitemap.xmlWhen configured poorly, this publicly accessible file can cause a great deal of crawling issues for a website.
For example, when I started a new role in-house, I came across the following:
User-agent: *
Disallow: /And this immediately rang alarm bells.
This is why robots.txt is one of the first things I look at when doing a technical SEO sweep.
In this guide, I am going to walk you through some of the most common issues you should look for in a robots.txt file.
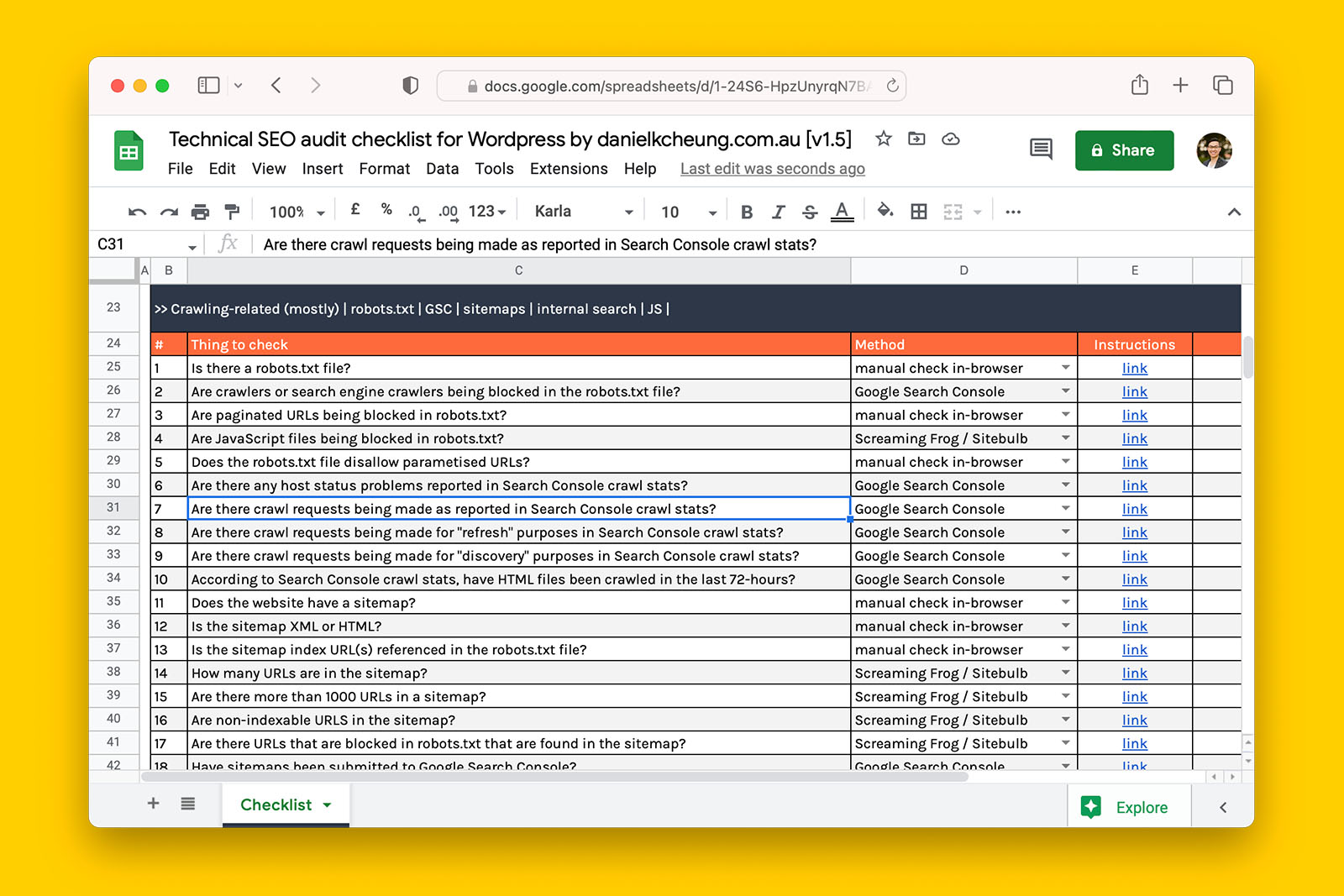
You can follow along by using my technical SEO audit checklist.
Let’s get started!
Is there a robots.txt file?
Background information:
- Not all websites have a robots.txt. In such cases, search engines will crawl everything because no rules have been defined.
- This is not a bad thing and is perfectly normal for smaller websites with less than a hundred webpages.
- Larger websites with thousands of URLs can benefit from having a robots.txt file.
- But when configured incorrectly, a robots.txt can easily prevent a website from being found on Google search.
How to check if a website has a robots.txt file:
- Append “robots.txt” to your root domain (e.g., www.danielkcheung.com/robots.txt)
- If the page loads in your browser, a robots.txt file exists
- In this instance, mark ‘yes’ in the checklist
- If you get a 404 error, a robots.txt filed does not exit
- In this instance, mark ‘no’ in the checklist
Possible answers:
- yes
- no
- not applicable
What this means:
> If ‘yes’, review if any crawlers and search engines have been blocked.
>> If ‘no’, consider creating and uploading a robots.txt file especially if you suspect Google is having difficulty discovering your URLs.
Recommended reading:
- ‘robots.txt introduction and guide’ by Google Developers
- ‘robots.txt for SEO: the ultimate guide’ by ContentkingApp
- ‘robots.txt – everything SEOs need to know’ by Lumar
Are crawlers or search engine crawlers being blocked in the robots.txt file?
Background information:
- The role of the robots.txt file is to instruct one or more search engines which files and URL paths it can crawl
- You can apply rules to all search engines or give specific rules to a particular search engine
- Therefore, it is perfectly normal to see certain crawlers being blocked from certain files and URLs
How to check if robots.txt is blocking Google using Search Console:
Note: the following does not work for Domain-verified GSC properties – if you don’t have URL-prefix properties, use the manual eyeball test
- Go to Google’s Robots Testing Tool
- Scroll through the robots.txt code to locate any highlighted syntax warnings and logic errors
- Type in the URL of a page on your site in the text box at the bottom of the page
- Select the user-agent you want to simulate in the dropdown list to the right of the text box
- Click the TEST button to test access
- Check to see if TEST button now reads ACCEPTED or BLOCKED to find out if the URL you entered is blocked from Google web crawlers
- Edit the file on the page and retest as necessary.
- Copy your changes to your robots.txt file on your site.
How to check if robots.txt is blocking any search engine manually:
- Open the robots.txt file in your browser
- See if any of the following instances exist in the file:
- User-agent: Googlebot
Disallow: / - User-agent: Bingbot
Disallow: / - User-agent: *
Disallow: /
- User-agent: Googlebot
- If you see any of the above instances, mark ‘yes’ in the checklist
- If you do not see any user-agents being blocked, mark ‘no in the checklist’.
For example:
User-agent: *
Disallow: /admin
Disallow: /cart
Disallow: /orders
Disallow: /checkouts/
Disallow: /blogs/*+*
Disallow: /blogs/*%2B*
Disallow: /blogs/*%2b*
Disallow: /*/blogs/*+*
Disallow: /*/blogs/*%2B*Possible answers:
- yes
- no
- not applicable
What this means:
> If ‘yes’, one or more crawlers or search engines are being blocked. This is not necessarily wrong and your next step is to understand what is being blocked and why.
>> If ‘no’, the robots.txt is not causing any crawling issues.
Recommended reading:
- ‘test your robots.txt with the robots.txt tester’ by Search Console Help
- ‘top 10 most popular web crawlers and user agents’ by KeyCDN
- ‘robots.txt introduction and guide’ by Google Developers
- ‘robots.txt for SEO: the ultimate guide’ by ContentkingApp
- ‘robots.txt – everything SEOs need to know’ by Deepcrawl
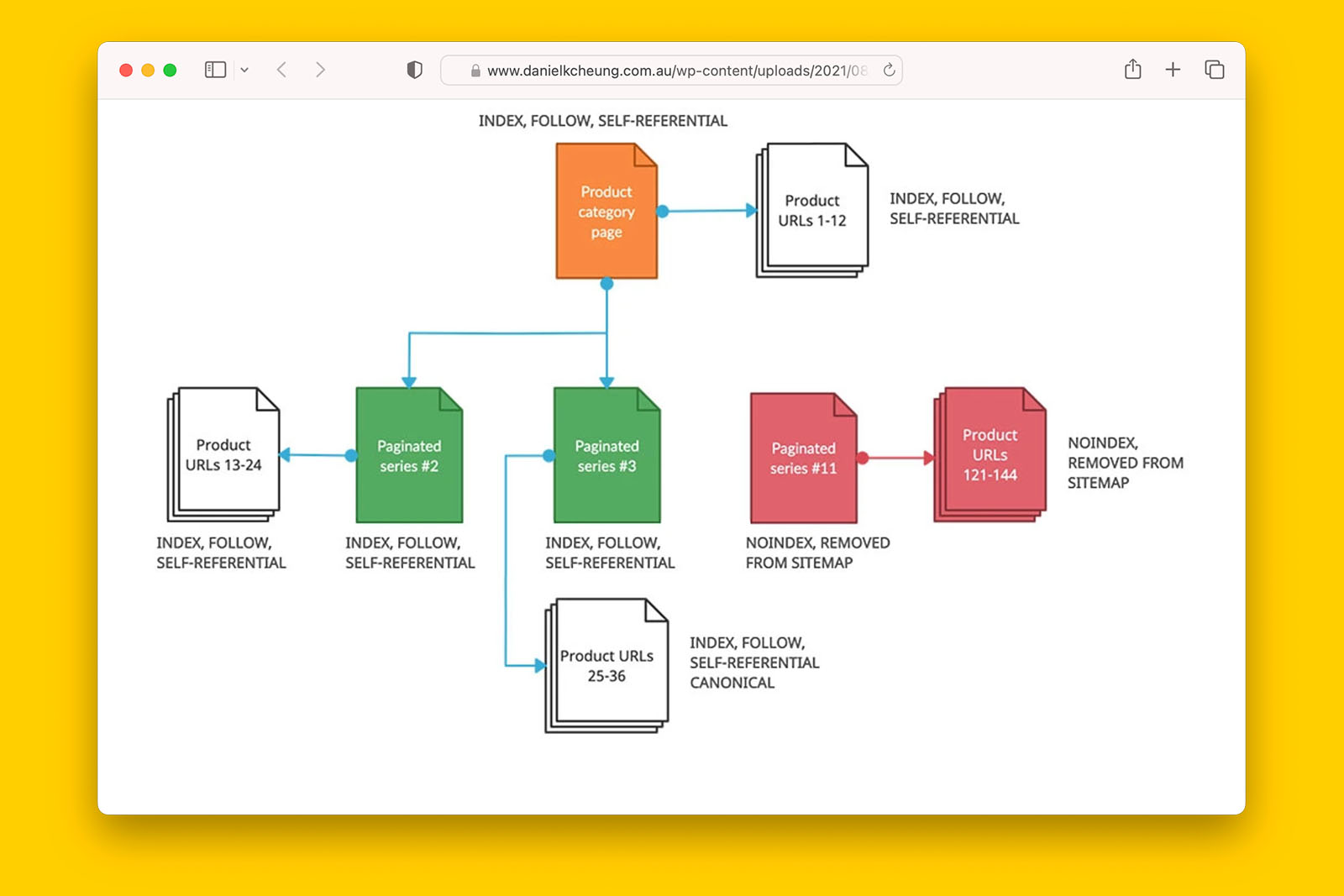
Are paginated URLs being blocked in robots.txt?
How to check if paginated series are being blocked in robots.txt:
- Open the robots.txt file in your web browser
- See if any of the following instances exist in the file:
- Disallow: /blog-page/page
- Disallow: /?page=
- Disallow: /&page=
- If you see any of these in the robots.txt file, check ‘yes’ in the spreadsheet.
What this means:
> If ‘yes’, verify with the site owner why this has happened. Paginated series should not usually be blocked in robots.txt although there are specific scenarios where this may be done.
>> If ‘no’, the robots.txt is not causing any crawling or indexing issues in relation to deeper URLs found on paginated series.
Recommended reading:
- ‘what happens to crawling and Google search rankings when 67% of a site’s indexed urls are pagination?’ by Glenn Gabe
- ‘pagination for SEO’ by prerender.io
- ‘pagination best practices for ecommerce websites’ by Daniel K Cheung
- ‘robots.txt introduction and guide’ by Google Developers
- ‘robots.txt for SEO: the ultimate guide’ by ContentkingApp
- ‘robots.txt – everything SEOs need to know’ by Deepcrawl
Are JavaScript files being blocked in robots.txt?
How to find out if JS is being blocked in robots.txt using Screaming Frog:
- Go to CONFIGURATION > SPIDER > RENDERING and change rendering from “text-only” to “JavaScript”
- Change AJAX TIMEOUT from 5-seconds to 8-seconds then click the OK button
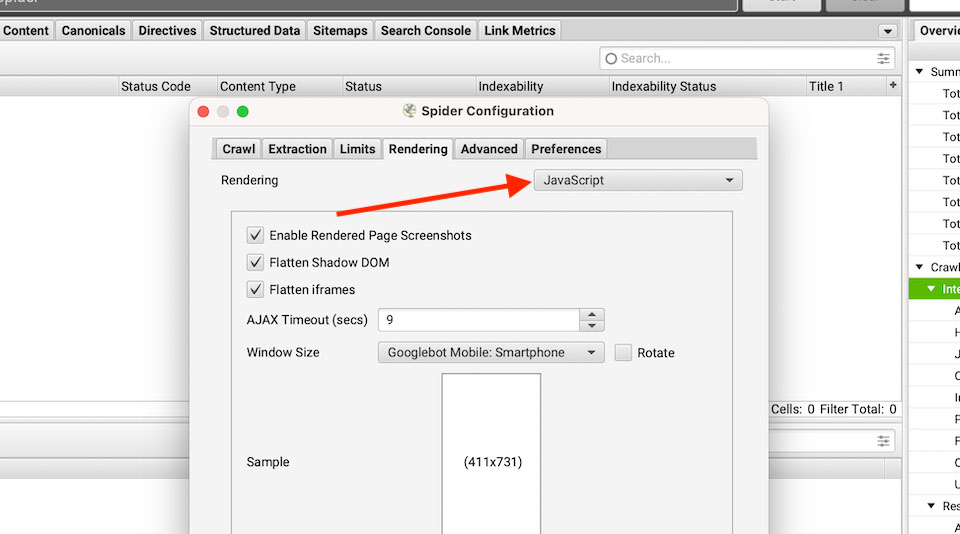
- Crawl the entire site, a section within the website, or a sample of the website
- Select any HTML file that has been crawled and navigate to RENDERED PAGE tab
- See if the content of the page has loaded
- If you do not see the page loaded correctly in the RENDERED PAGE tab, proceed to the next step
- If you see the page load correctly, proceed to the next step to verify if JS are blocked in robots.txt file
- Go to BULK EXPORT > RESPONSE CODES > BLOCKED BY ROBOTS.TXT INLINKS and open the .csv file and scan for JS that has been blocked in robots.txt
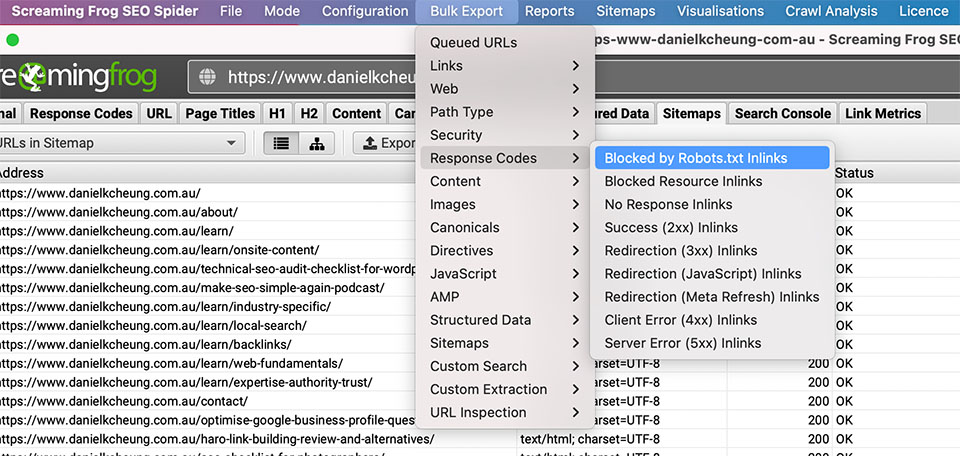
How to find out if JS is being blocked in robots.txt manually:
Note: For most WordPress websites, JavaScript comes from the theme and is typically housed in ../wp-content/themes/yourTheme. Therefore, load the robots.txt file in a web browser and see if /wp-content/ is in the file.
Possible answers:
- yes
- no
- not applicable
What this means:
> If ‘yes’, JS is being blocked and this may be making it harder for Google to render the content on the pages you want to rank.
>> If ‘no’, JS files are not being blocked from crawlers in the robots.txt file. If the website is experiencing indexing issues, this is not the cause.
Recommended reading:
- ‘wordpress robots.txt guide’ by Kinsta
- ‘robots.txt introduction and guide’ by Google Developers
- ‘robots.txt for SEO: the ultimate guide’ by ContentkingApp
- ‘robots.txt – everything SEOs need to know’ by Deepcrawl
Does the robots.txt file disallow parametised URLs?
How to check if parametised URLs are blocked in robots.txt:
- Open the robots.txt file in your web browser
- See if any of the following instances exist in the file:
- User-agent:*
Disallow: /products/t-shirts? - User-agent:*
Disallow: /products/jackets?
- User-agent:*
- If you do, check ‘yes’ in the spreadsheet.
Possible answers:
- yes
- no
- not applicable
What this means:
> If ‘yes’, one or more parametized URLs are blocked in robots.txt. In most use cases, parametised URLs should not be disallowed in robots.txt file because Googlebot cannot read the rel-canonical if it has been blocked from crawling said parametised URL.
>> If ‘no’, there is another reason why the website is experiencing indexing issues.
Recommended reading:
- ‘Google: do not use robots.txt to block indexing or URLs with parameters’ by Search Engine Roundtable
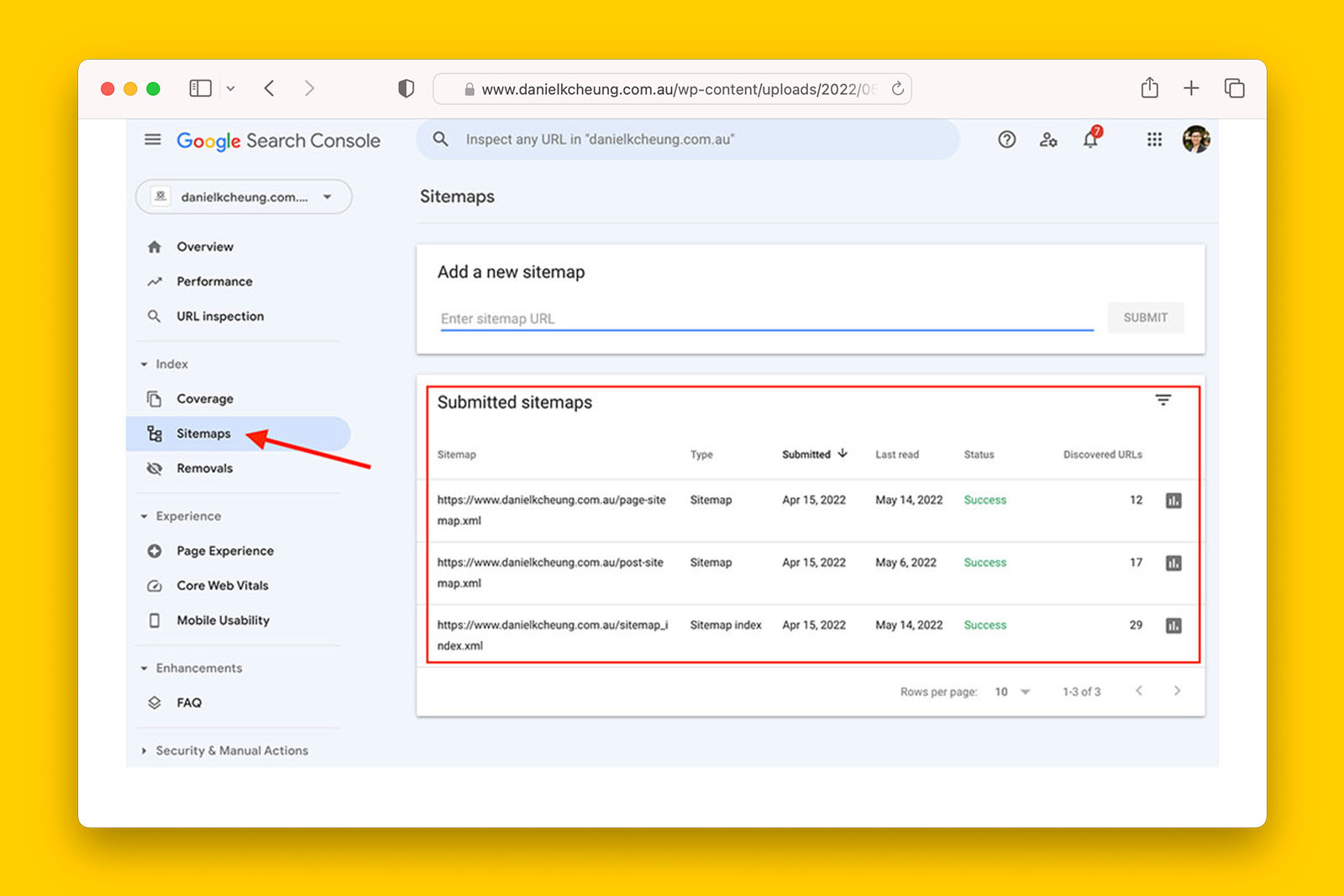
Is the sitemap index URL(s) referenced in the robots.txt file?
Background information:
- Adding a sitemap can help a search engine crawl a website more efficiently
- This can be done by putting the full URL of the XML sitemap file
- More than one sitemap can be referenced in the robots.txt file
User-agent: *
Disallow: /references/
Disallow: /merchants/
Disallow: /mobile/
Sitemap: https://www.commbank.com.au/sitemap.xml
Sitemap: https://www.commbank.com.au/content/dam/commbank/root/articles-sitemap.xmlHow to check if robots.txt mentions the sitemap address:
- Open the robots.txt file in your browser
- Search for “sitemap” and see if a full URL has been provided
- If you see this, check ‘yes’ in the spreadsheet
- If you do not find “sitemap” in the robots.txt, check ‘no’ in the spreadsheet
- If there is no robots.txt file, check ‘not applicable’ in the spreadsheet
Possible answers:
- yes
- no
- not applicable
What this means:
> If ‘yes’, the sitemap is referenced in robots.txt and crawlers such as Googlebot can easily find and crawl it.
>> If ‘no’, the sitemap is not referenced in robots.txt. As long as the sitemap has been submitted to Google Search Console, this is not a red flag. If no sitemap has been submitted to GSC, this should be something you address ASAP if crawling and indexing is an issue.