Why do WebP and WebM files show up as ‘Crawled – currently not indexed’ in Google Search Console?
A WebP file is an image file format developed by Google that uses both lossy and lossless compression. It was designed to be an alternative to the popular JPEG, PNG and GIF image formats with the goal delivering high image quality in a smaller file size footprint..
Similarly, a WebM file is a video file format developed by Google that was designed to provide a smaller file size while maintaining good video quality.
If you have ever run a PageSpeed Insight report, you will be familiar with the following recommendation: “Serve images in next-gen formats”.
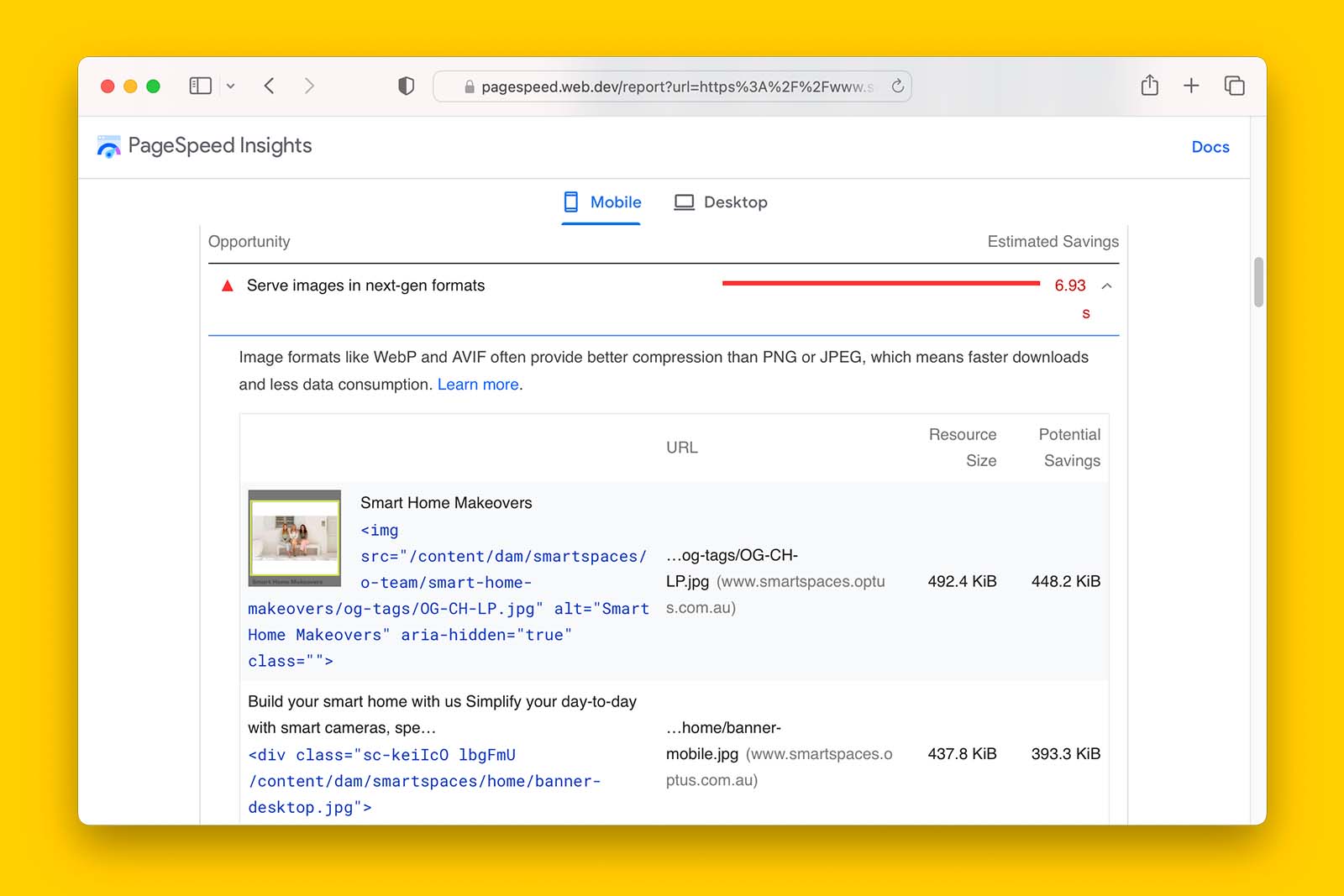
Google’s documentation offers the following guidance:
AVIF and WebP are image formats that have superior compression and quality characteristics compared to their older JPEG and PNG counterparts. Encoding your images in these formats rather than JPEG or PNG means that they will load faster and consume less cellular data.
https://developer.chrome.com/docs/lighthouse/performance/uses-webp-images/
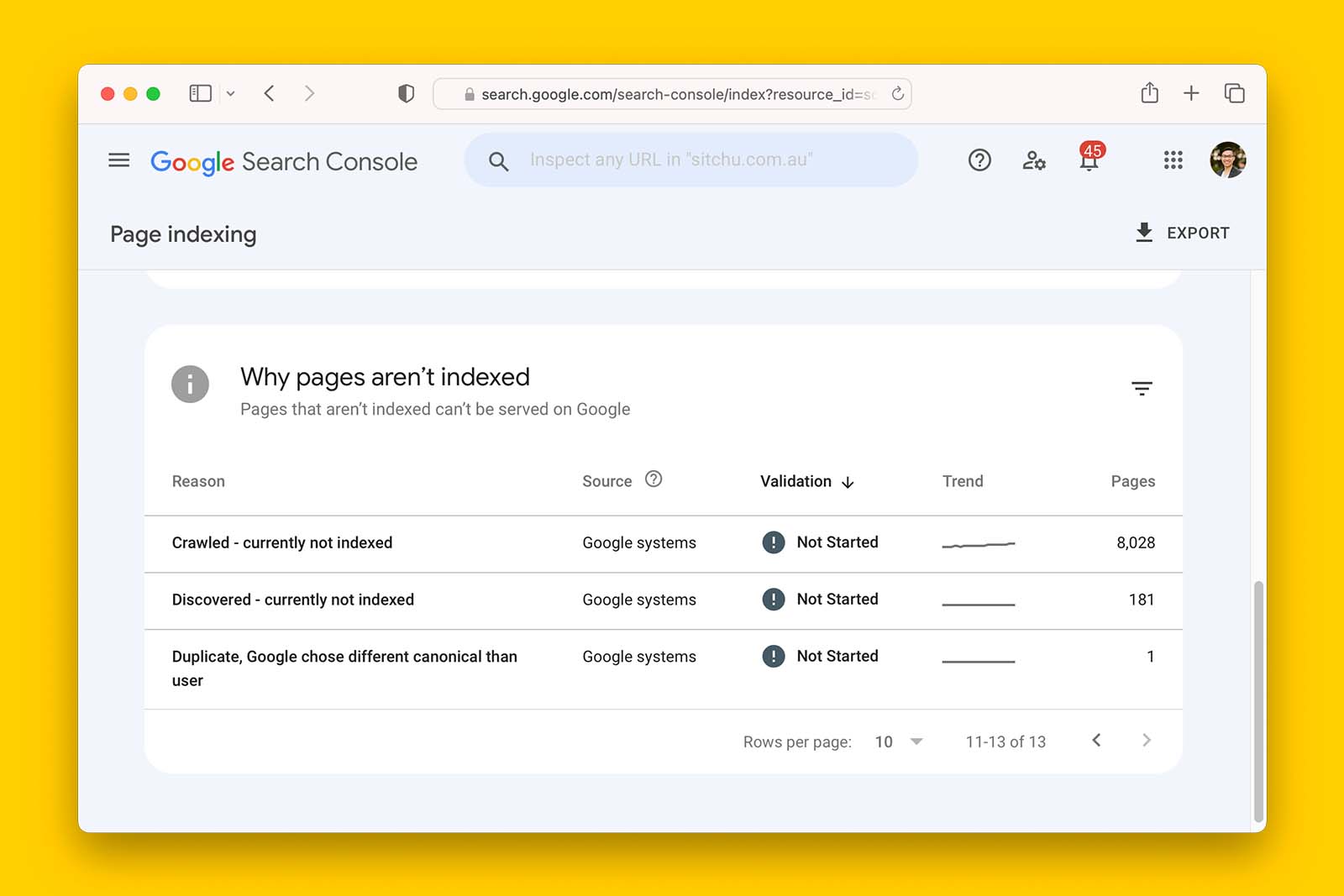
Question: If WebP and WebM are both media formats developed and recommended by Google, why are they showing up as ‘Crawled – currently not indexed’ in Search Console?
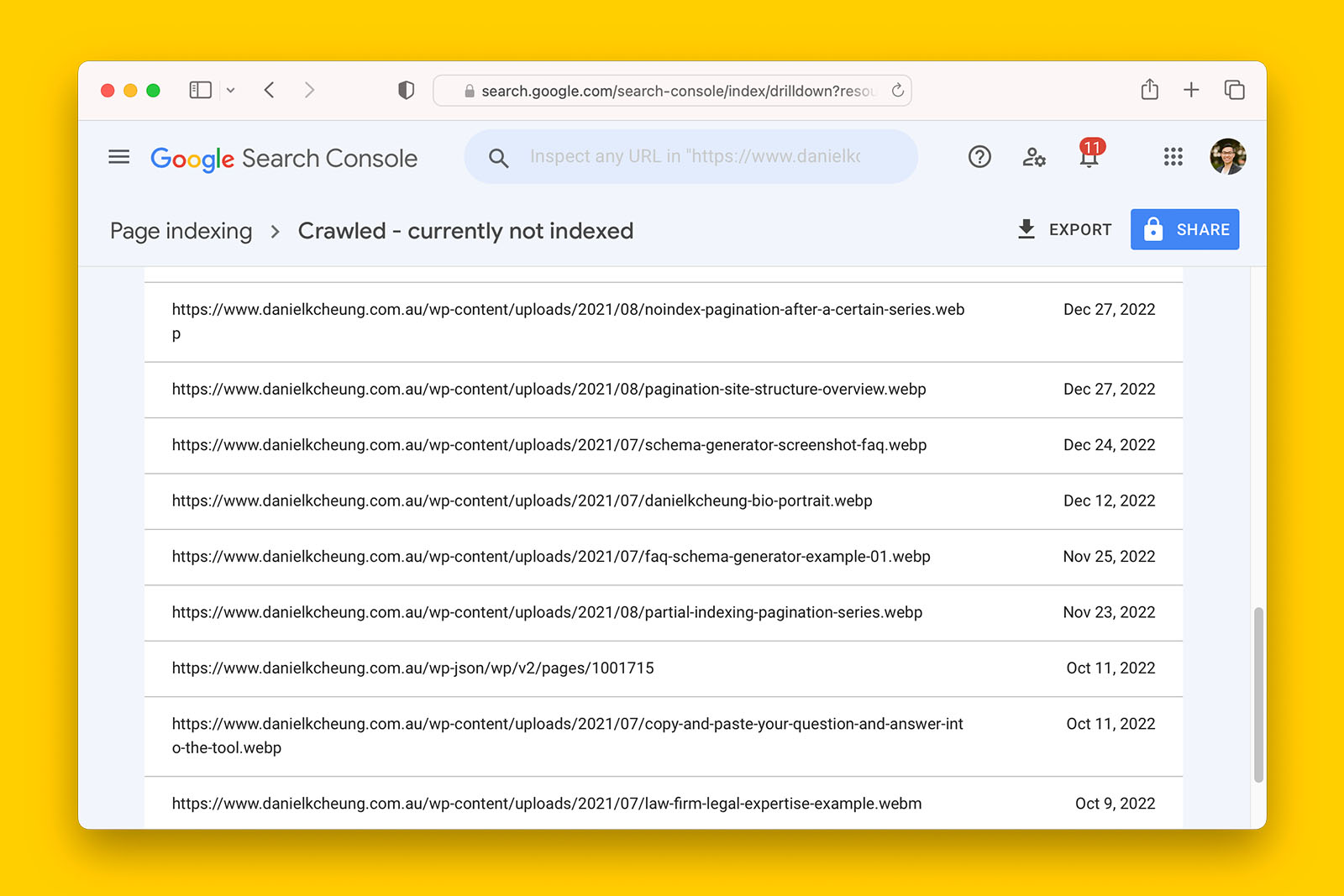
Answer: This is because Search Console reports on pages while WebP and WebM are files.
This is more a bug of the tool than an issue you should worry about and it is not an indication that Google doesn’t know how to crawl, render or index WebP or WebM media.
But what if you want to know if an image has been indexed by Google?
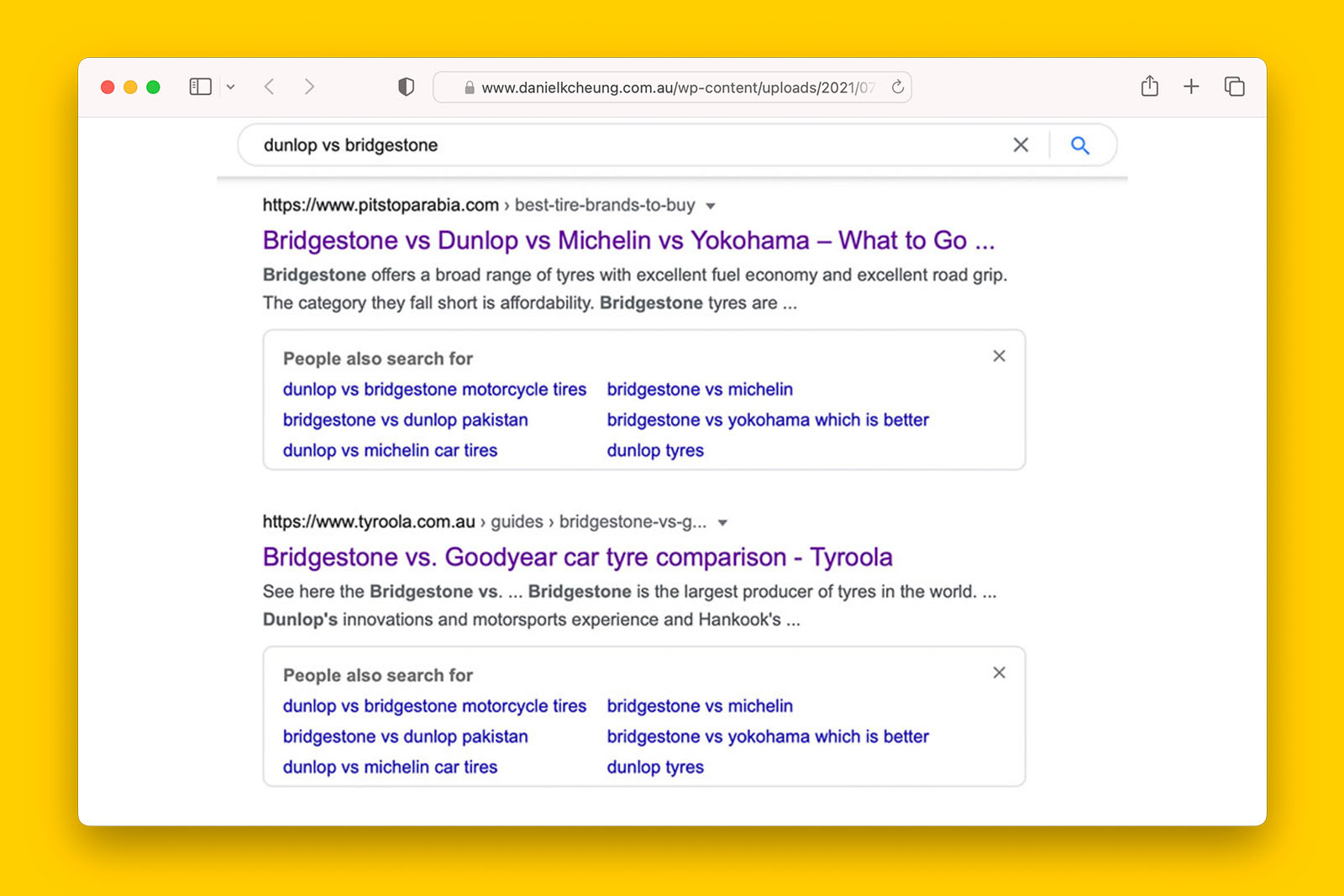
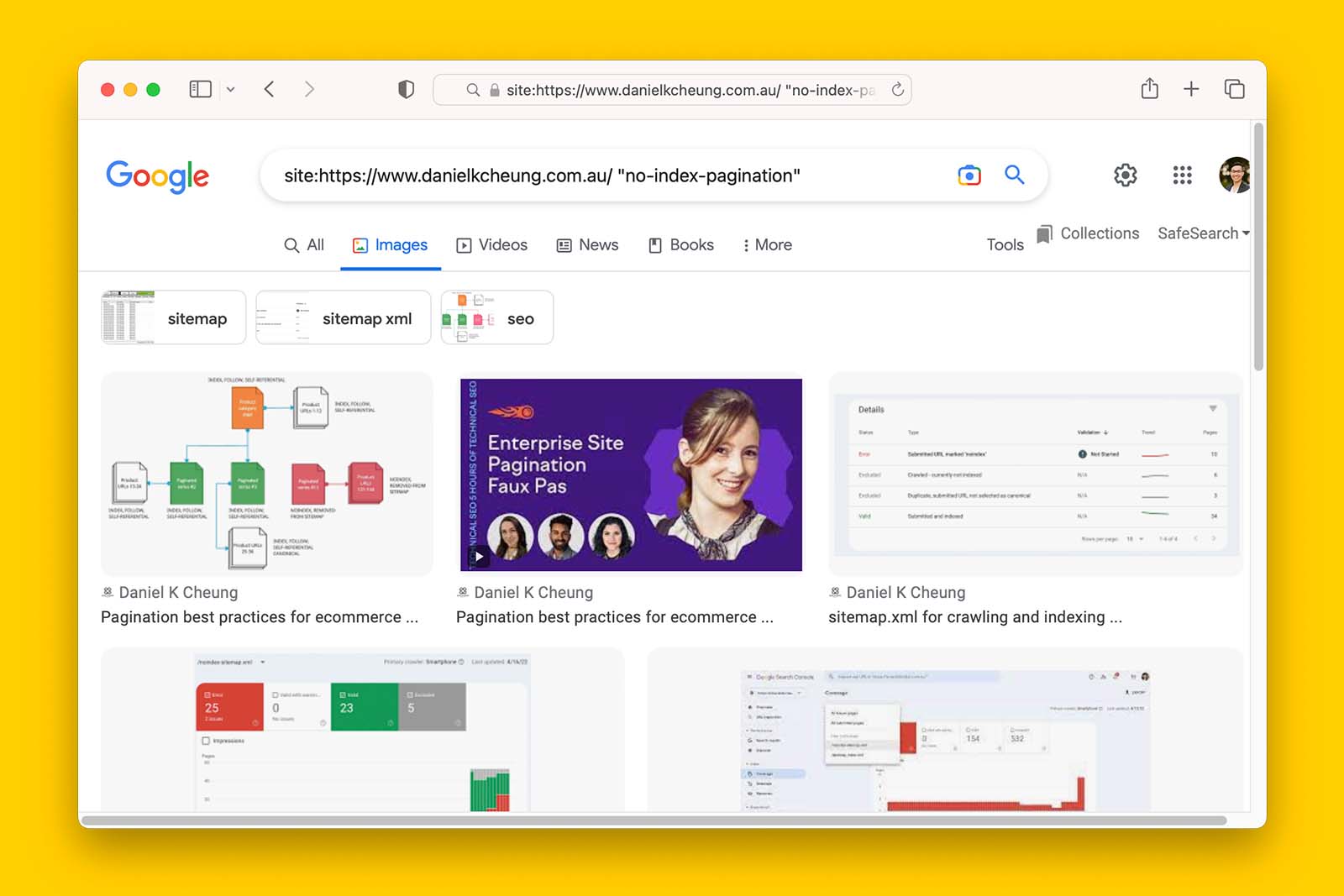
Since Search Console only reports on webpages, you cannot put in the URL of an image to check its coverage. Instead, you can use a site: search operator on Google Image search.
site:https://www.danielkcheung.com "noindex-pagination"This is because a site: query is a search operator that allows you to request search results from a particular domain or URL. And this type of query works because it is available on all Google Search properties (source).
By doing so, Google Images returns images that show up for the term “noindex-pagination” – which happens to be part of the WebP filename.
In summary, you can ignore WebP and WebM files reported as ‘Crawled – currently not indexed’ because GSC provides data on webpages, not individual files.
You can always check if the file has been indexed by using the site: search operator in Google Images or Google Videos search.
Pages reported as ‘Crawled – currently not indexed’, however, is a different issue. You can learn more in my guide ‘How to diagnose and fix crawled – currently not indexed pages’.