Schema markup template: Boost the EEAT of your YMYL content with interconnected entities
Key takeaways:
- The ‘who’ behind the content is an important element of Google EEAT for YMYL verticals – just as important, if not more important than the content itself.
- Structured data is an effective way to communicate who researches, writes, edits and reviews your content, especially for YMYL topics.
- Schema markup will not magically improve your EEAT but if it reflects the expertise and experience of your writers, contributors, editors, and reviewers, Google will use this information and validate it from external sources. This is experience, expertise, authoritativeness and trustworthiness.
- This JSON-LD template can be used on any informational webpage on any website.
- However, for best results, Person schema is best reserved for the individual’s entity home.
What is a schema markup template and what problem does it solve?
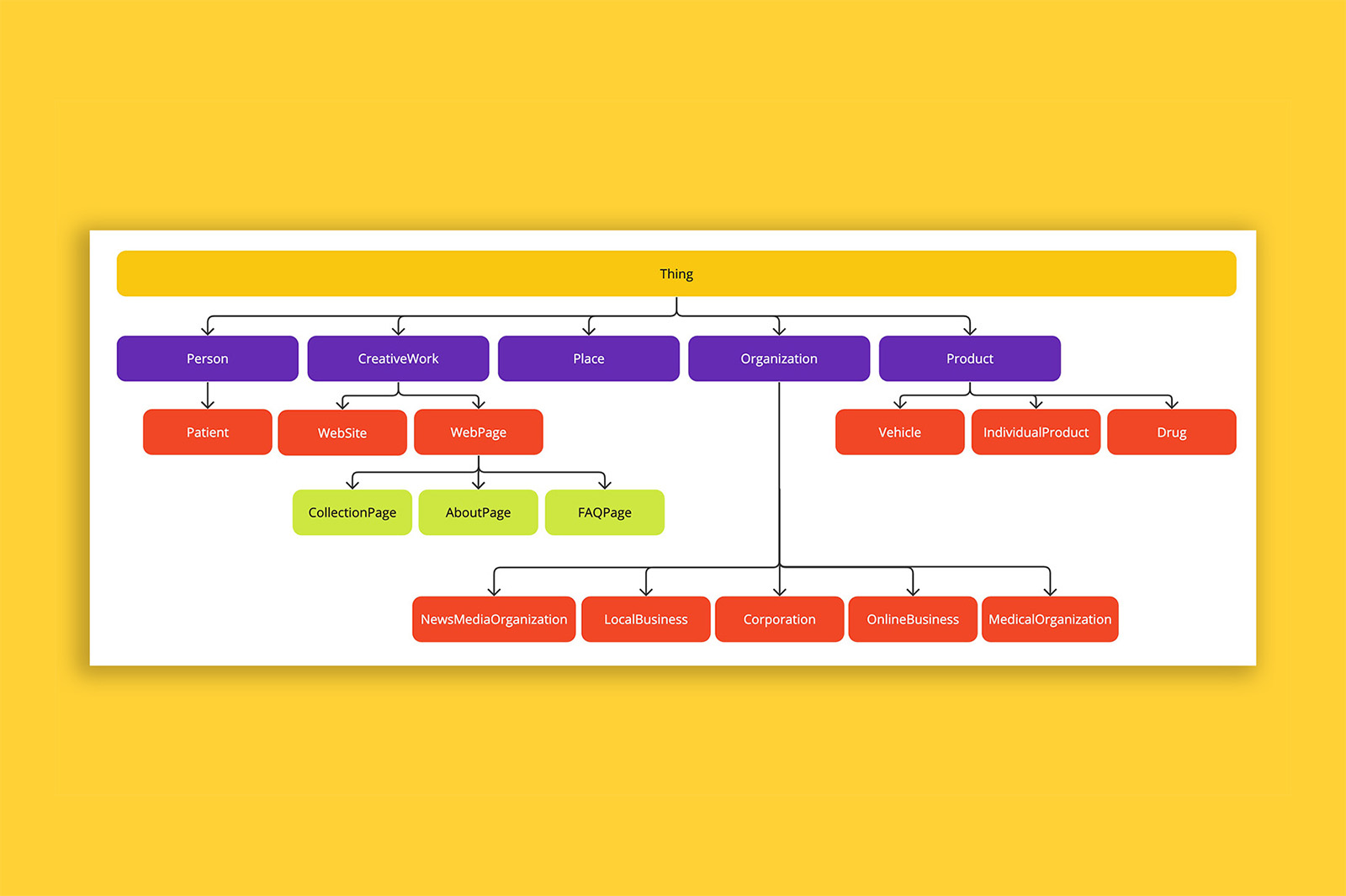
A schema markup template is a JSON file with pre-populated Schema.org vocabularies. What makes this schema markup template useful is that the entities you will need (e.g., Person, Organization, WebPage, FAQPage) are already joined together to create a page-level knowledge graph.
In this case, the template is designed for informational articles in the “your money, your life” type of topics such as:
- Best business loans for small businesses
- What are the health benefits of CBD oil?
- How should I respond to gaslighting in the workplace?
- Are ETFs safe?
- How to pick a crytocurrency wallet
All you will need to do is fill out the relevant values and add the code to the webpage you’re marking up.
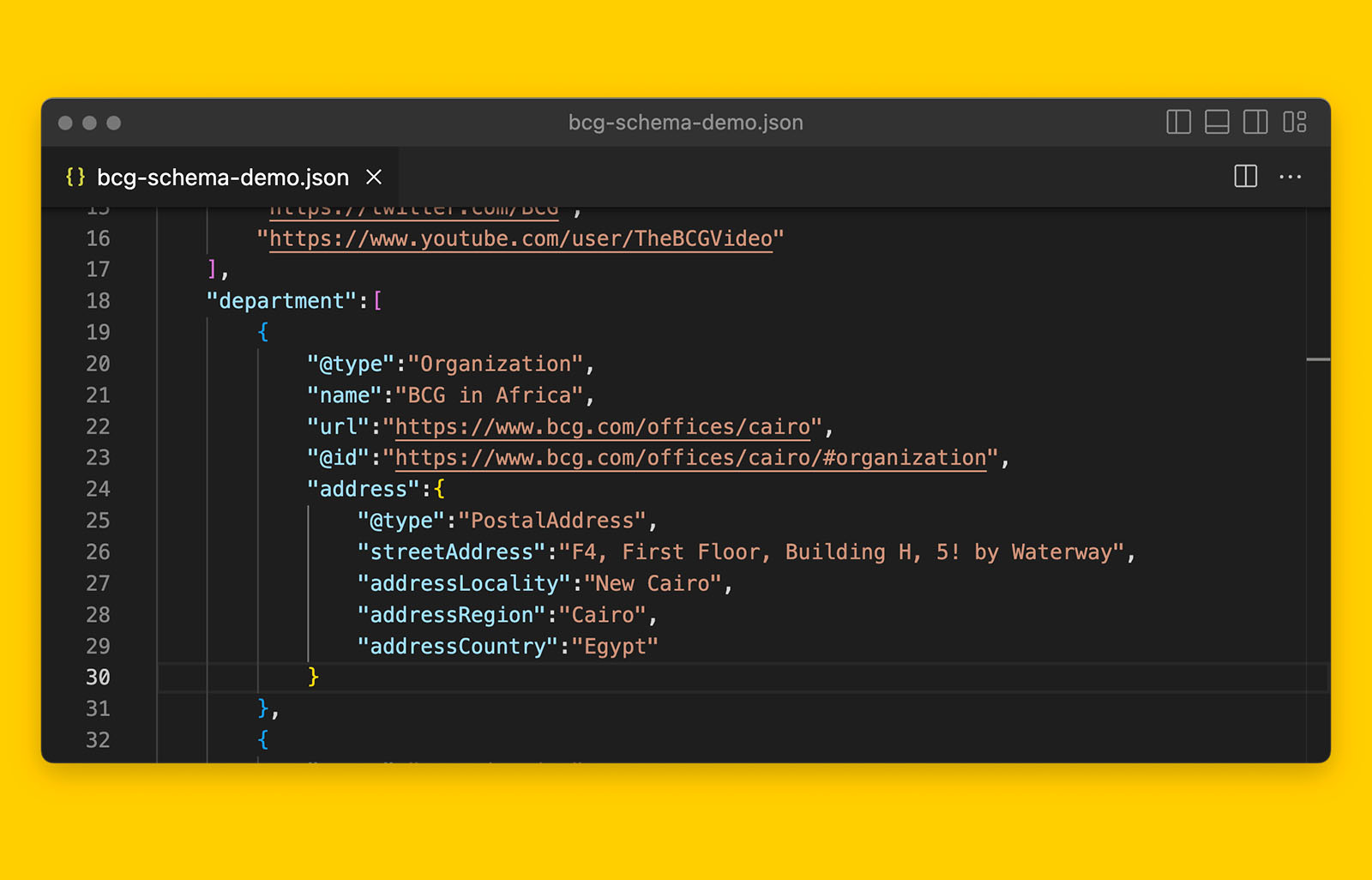
By the way, this is what the template looks like.
The ‘EEAT Supporting Schema Template For YMYL Informational Articles’ will let you effectively demonstrate how your content meets the expertise and experience requirements for YMYL content by describing in granular detail who authored the content, who researched the content, and who fact checked the content.
More importantly, the template will help you create a page-level knowledge graph of all the necessary entities and their relationships with ease.
What’s included?
You will receive nine (9) JSON files:
- Two files are editable templates made for an article with a FAQs component
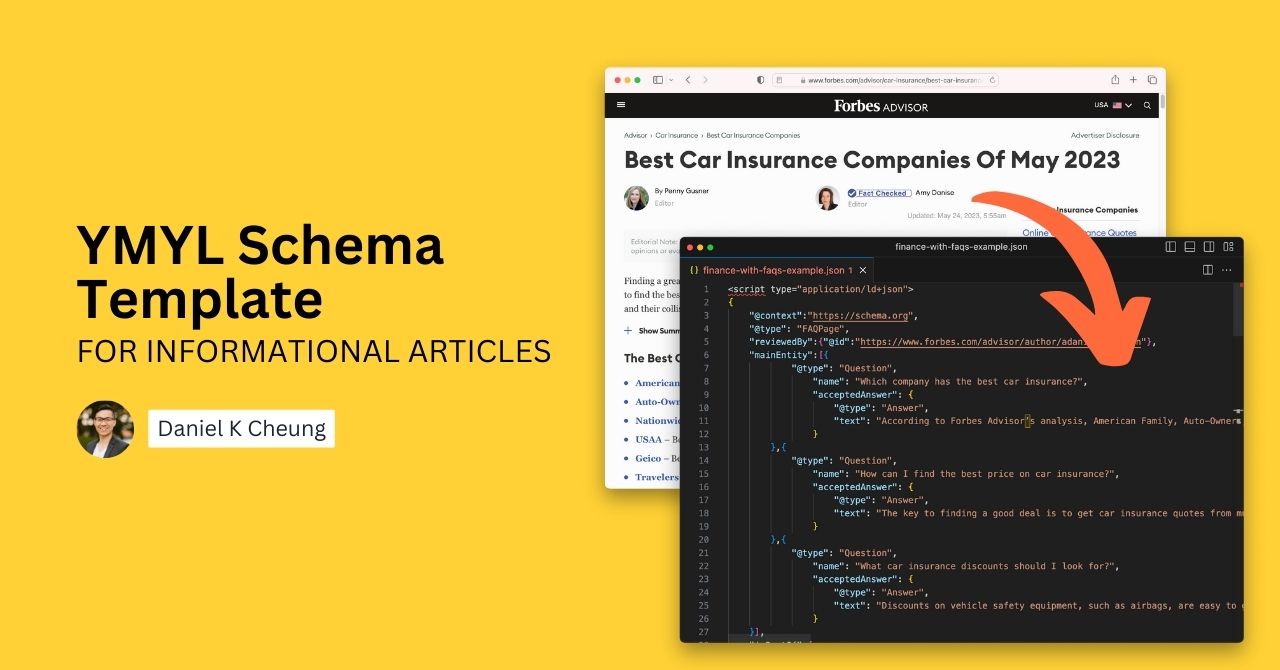
- Two files are done-for-you nested schema markups based on https://www.forbes.com/advisor/car-insurance/best-car-insurance-companies/
- Two files are editable templates made for an article without any FAQs
- Two files are done-for you examples based on https://www.chase.com/business/knowledge-center/grow/7-ways-finance-small-business
- One .json file is a done-for-you example based on https://www.sage.com/en-us/blog/how-to-build-a-winning-revenue-operations-strategy/ with Person schema type
Save time and demonstrate EEAT effectively – buy the template on Gumroad.
What does the template do?
The primary goal of marking up your informational pages with schema is to communicate why Google should trust your content over other sources.
Rather than focusing on the overall topic of the article, the template explains to Google how the content meets its EEAT requirements. It does this by describing all the people involved with the publishing of the information.
🚨 This means that you will need real people behind your content. If you do not have these then this template is useless to you.
Communicating what the content is about is a secondary objective of this schema template.
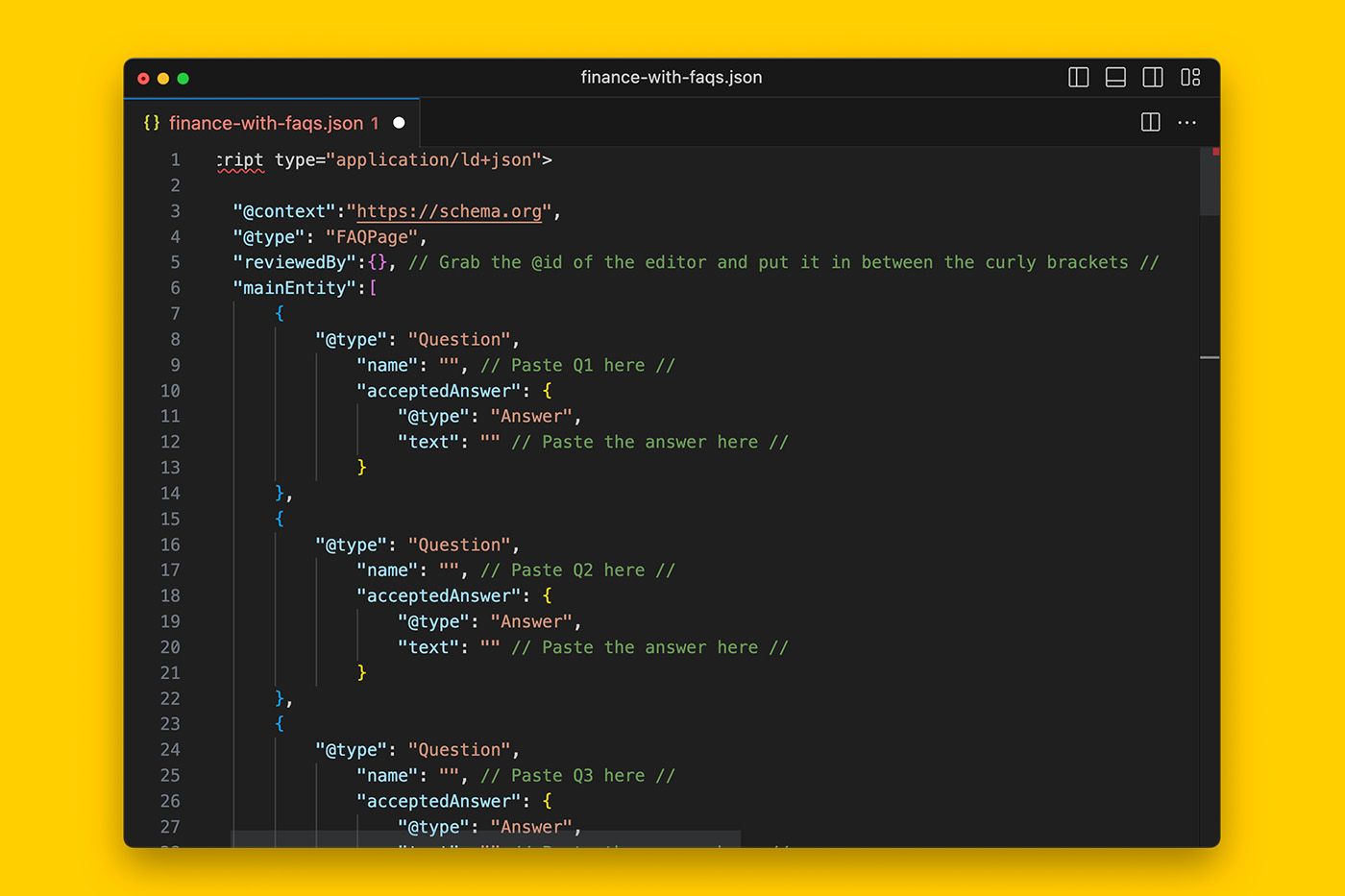
To do this, the JSON-LD template will allow you to tell Google:
- There is a FAQ section with 3 questions and answers that is part of the Article.
- The FAQs have been reviewed by a person (who’s identity, experience and qualifications will be described shortly).
- The Article (which the FAQs are part of), has a feature image
- This image is about the same thing as the Article and should therefore be associated with the target keyword.
- There is intended audience for the Article.
- The Article mentions one or more things where each of these things are referenced to a Wikipedia or WikiData database entry so that there is no confusion what the Article is about.
- The Article is part of a WebPage where there is a target keyword.
- This WebPage is related to other WebPages, in particular, one specific WebPage that is most relevant.
- The WebPage has one or more authors and there are credentials that explain why they’re experienced and experts in the subject matter.
- The WebPage has been reviewed by a person and there are credentials that explain why they’re fit for the task.
- The WebPage is part of a website that is published by an Organization.
What does the template look like?
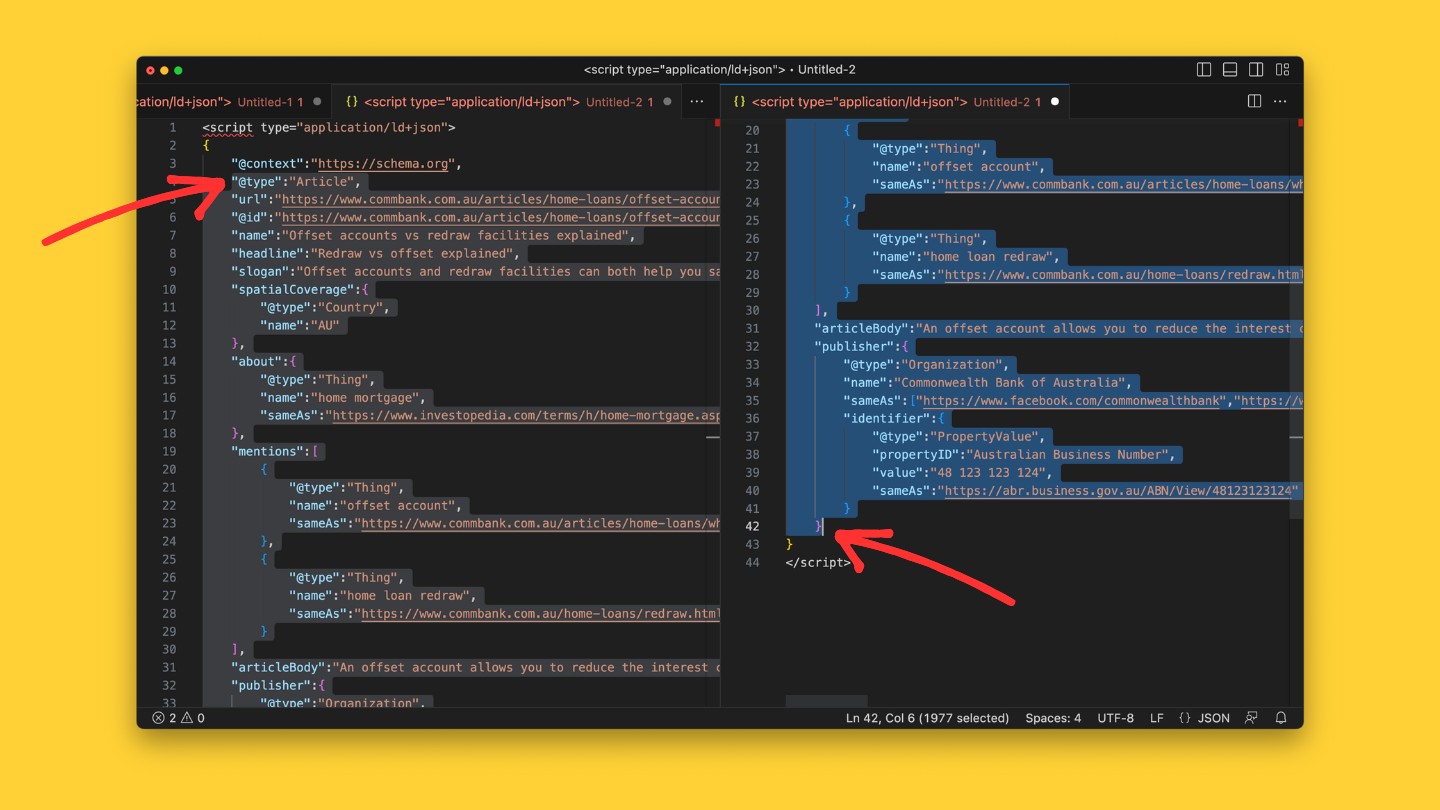
Each JSON file is wrapped between <script> tags. This is done so that you can easily add them to the <head> of the corresponding informational page.
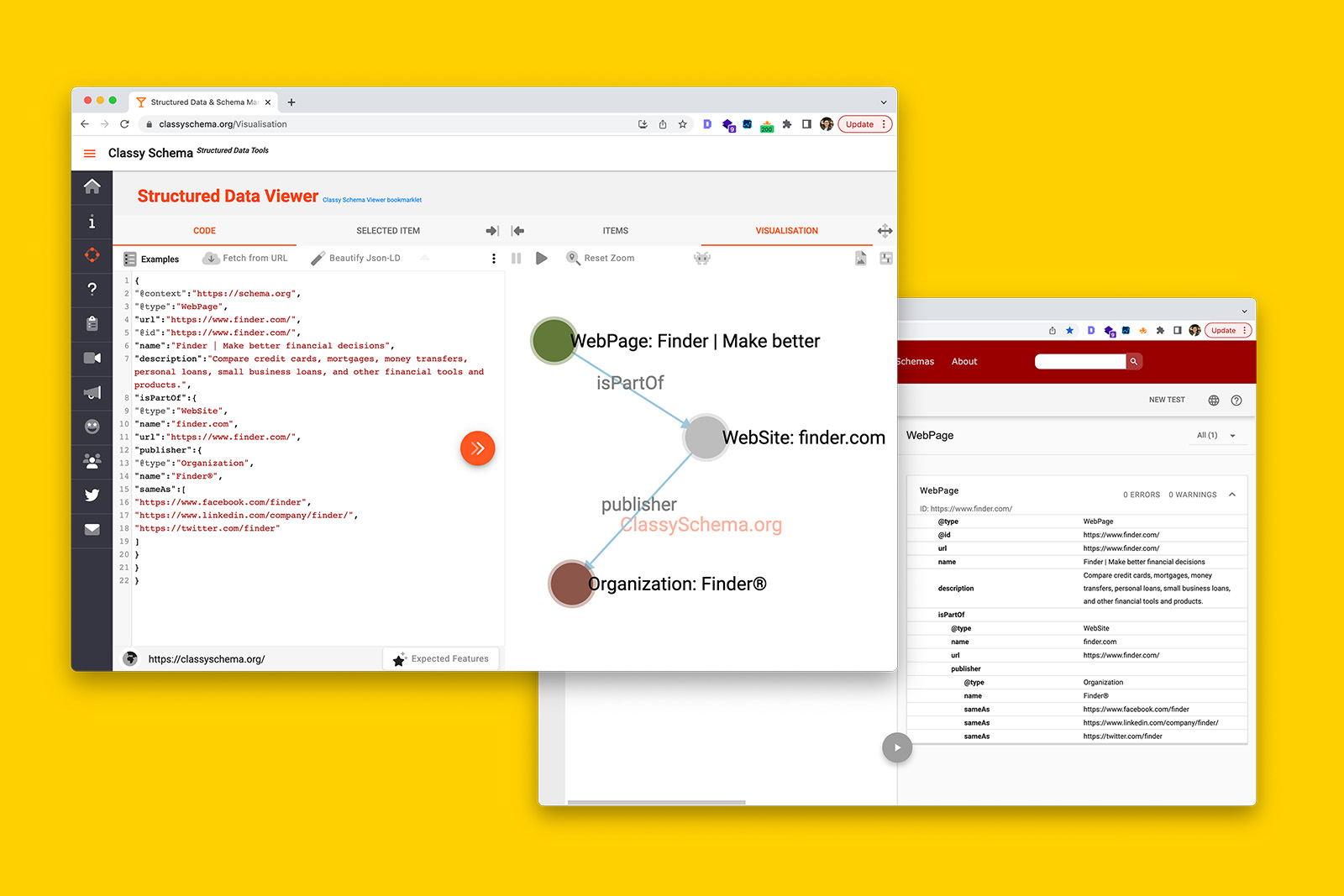
Written in JSON-LD syntax, the template covers the most common schema types you will need to communicate the credibility of your content and when you open the JSON file, it will look like this.
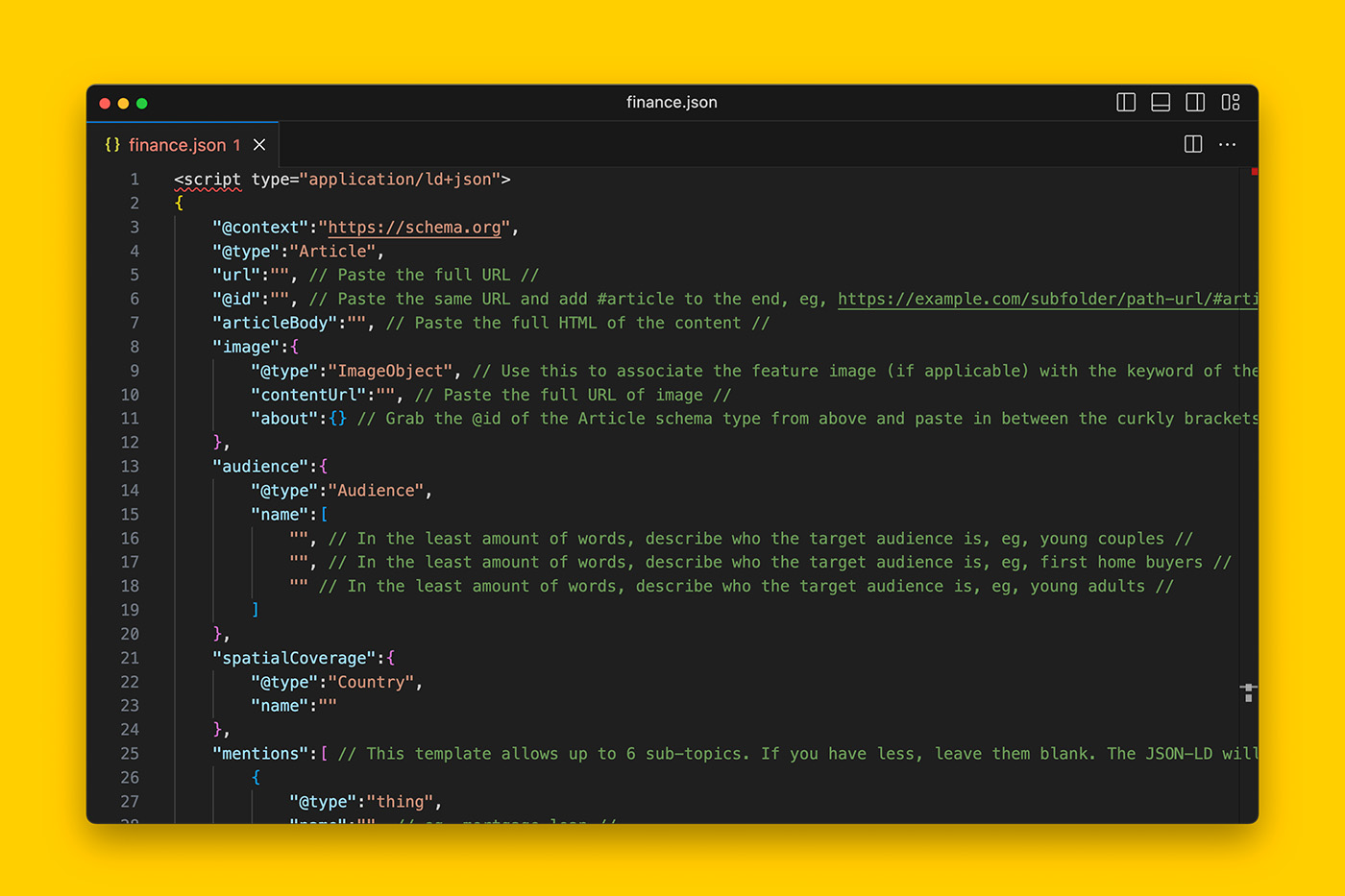
- Text in orange are schema types.
- Text in blue are Schema.org item properties. Essentially they’re attributes that let you describe each schema type in detail.
- Notes (in green) will tell you what type of value or input is required per attribute.
Get the template
Download the YMYL schema template on Gumroad.
Frequently asked questions
Anyone who manages a website that has YMYL content will benefit from this template.
If your content covers news and current events, finance, health, safety and well-being, and you have real authors, editors, contributors, and fact-checkers on your team – semantic SEO will help Google validate their identities, their experience, and expertise.
This can include affiliate webmasters, niche website owners, SEO managers, SEO specialists, and even content writers who want to upskill so that they can charge more by offering more value.
Skip the learning curve of learning JSON-LD syntax.
Save yourself from the hours of frustrating as to why Schema.org validator is telling you there is a missing comma or curly bracket.
>> Download the pre-populated JSON-LD template for YMYL content on Gumroad.
You don’t have to disclose the people behind your content but this will impact the validity and credibility of your content.
Affiliates have a bad reputation for publishing YMYL without proper disclosure. In recent years, content with affiliate links have been pushed down the SERPs and Google has been pushing for experience, expertise, authoritativeness and trustworthiness.
One way to do this is telling your audience who researched your content and why they should trust them.
To learn more, read ‘Creating helpful, reliable, people-first content’ published by Google.
If you do not wish to disclose this type of information for YMYL content, active link-building is your best bet.
Alternatively, you can describe the author of the content as the organization itself. That is, instead of using Person schema.org Type, use Organization Type.
Once you have purchased the template you will be able to download the JSON files.
I recommend you use Visual Studio Code to open and edit the JSON files – especially if this is your first time with JSON-LD.
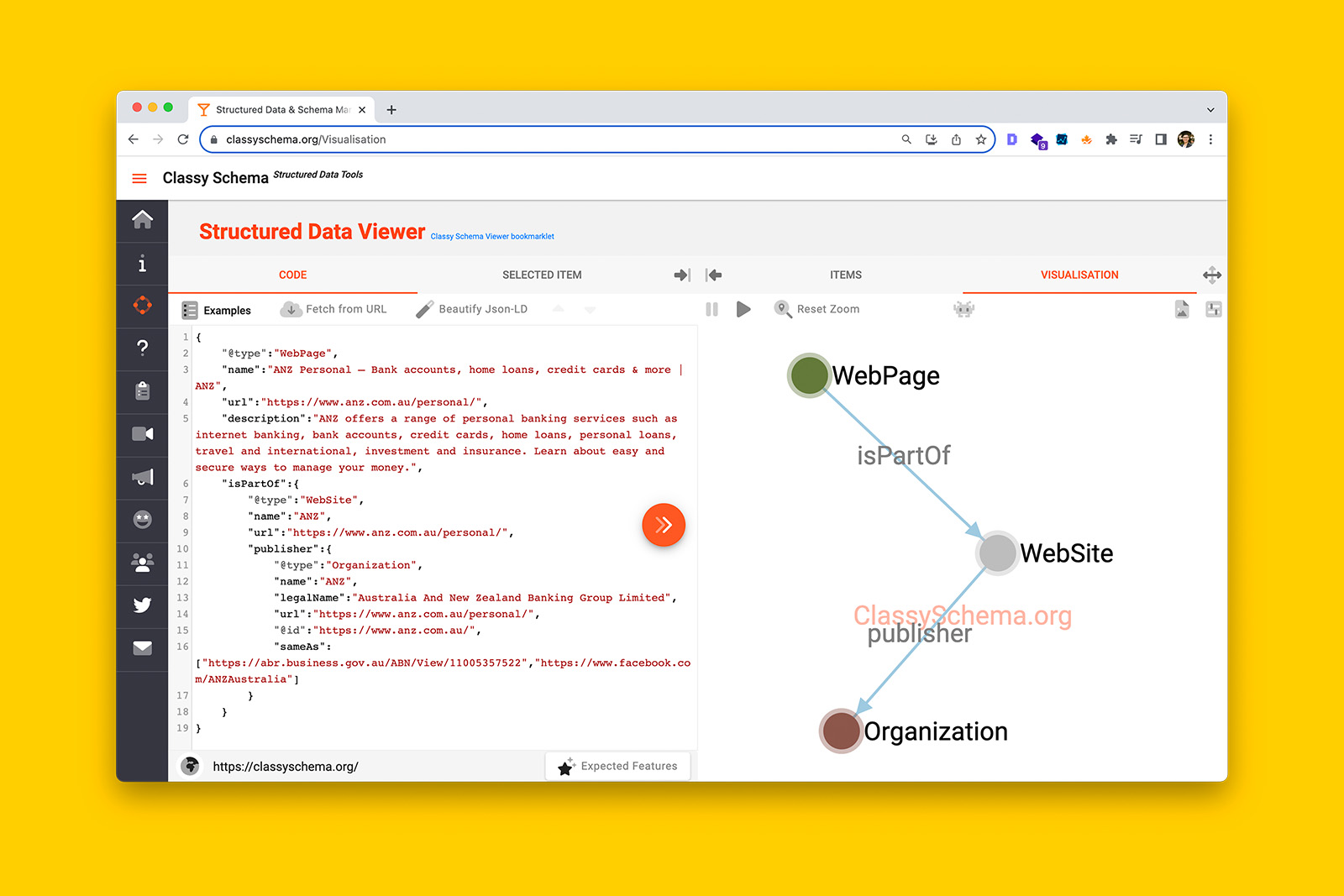
Upon opening the JSON file, you will see lines of colour-coded code:
- Text in orange are schema types.
- Text in blue are Schema.org item properties. Essentially they’re attributes that let you describe each schema type in detail.
- Notes (in green) will tell you what type of value or input is required per attribute.
You will see a lot of “” (in orange).
Add your values in between these double quotation marks – in doing so, you are effectively describing each entity.
Once you are done adding in relevant values, copy and paste it all and put it through both the Schema.org validator and Google Rich Results Test.
You can generally ignore non-critical issues flagged by Google Rich Results Test.
If you see an error reported in the Schema.org validator, you’ve probably made a syntax error. This means you have an extra or missing comma somewhere or an extra or missing closing curly bracket somewhere in the code.
Luckily, ChatGPT is pretty good at fixing these syntax errors.
Once your JSON-LD is validated, copy and paste all of it and insert it into the informational article’s <head>.
After which, you may perform a final validation with the live URL.
Watch the following video for a detailed explanation of how to get the most out of the schema template.
I recommend the following approach:
- Use all available Person schema properties on the person’s entity home. In many cases, this will be the author profile page.
- Use a simpler version of Person schema on all other pages. That is, you’re simply identifying who the person is and linking to person’s entity home.
Yes, you must disable any automated structure data generation on your webpage and/or website.
If you’re using Yoast or Rankmath to generate your schema, you must disable it before you add the JSON-LD manually to your pages.
If you don’t, you will have duplicate schema that will confuse search engines and they may ignore any and all of the markup.
The template leverages the attributes of Person schema and nests it within Organization, WebSite, WebPage and Article schema types.
You will be able to describe the following Person schema item properties:
- name
- honorificPrefix (for health content)
- honorificSuffix (for health content)
- sameAs (link to their LinkedIn and academic profiles)
- jobTitle
- knowsAbout
- alumniOf
For the article itself, you will be able use:
- image
- audience
- spatialCoverage
- mentions
- mainEntity
- isPartOf
For webPage schema, these attributes are available to you:
- keywords
- significantLink
- relatedLink
- author(s)
- reviewedBy
- contributor
- isPartOf (to nest the WebPage within WebSite schema)
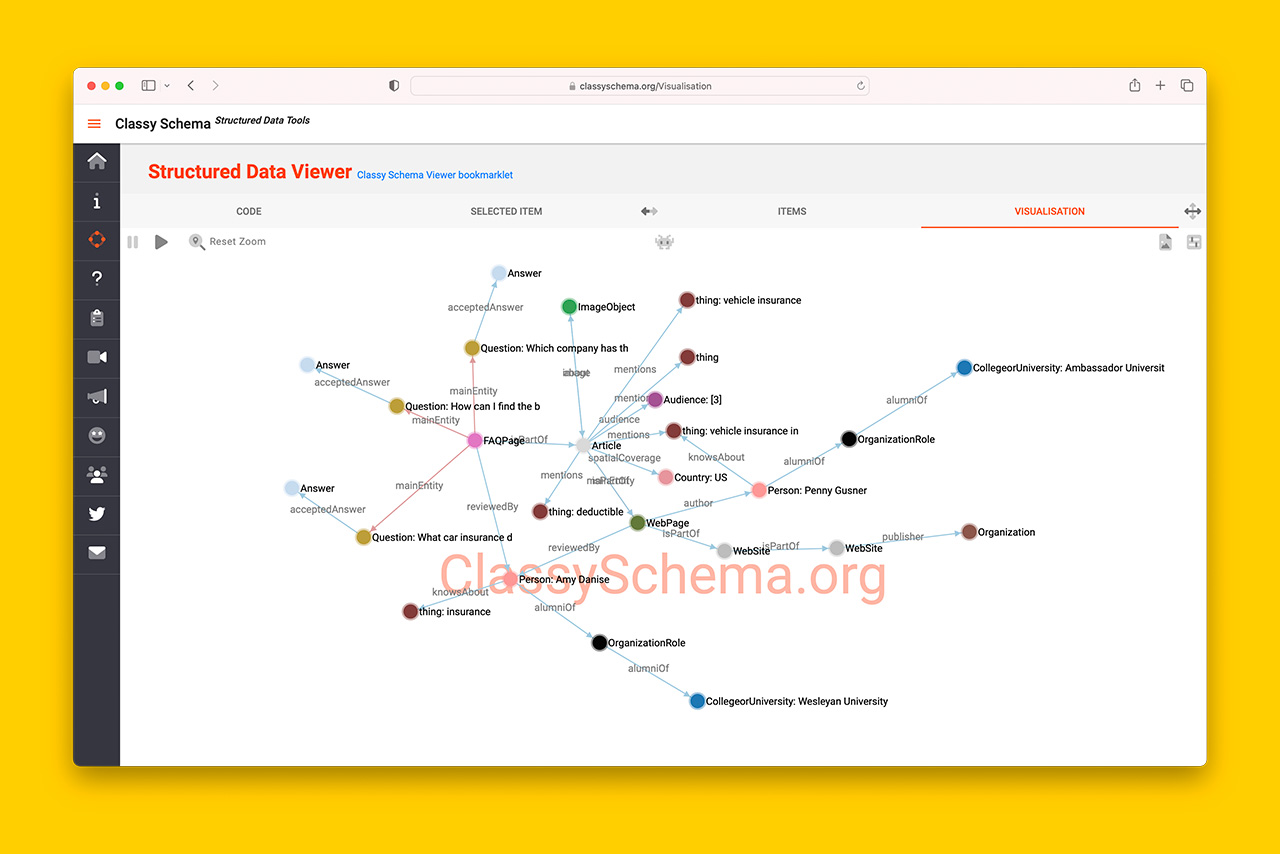
The end result of using the template is the creation of clear relationships between entities that look like this:
This template does not include these by default.
This is because the primary objective of the structured data is to communicate the experience and expertise of the people involved in the publishing of the content.
But this does not mean you cannot reference FinancialProduct, InvestmentFund, FinancialService or LoanOrCredit schema types because you can.
You can do this with the “mentions” item property that is nested within the webPage schema type.
For example:
"mentions":
{
"@type":"FinancialProduct",
"name":"Small Business Loan",
"offers":{
"@type":"Offer",
"offeredBy":"https://www.chase.com/business"
}
}No, you do not need to disclose every single person who was involved in the publishing of the content on the front-end.
You should, however, always disclose who the author of the content is. If you have an editor, you can disclose this information publicly as well.
However, if all your content is legally reviewed in-house before it gets published, you do not have to disclose who these individuals are on the front-end. But you can definitely reference your legal personnel in the schema markup.
The template is not designed for non-informational Articles.
Yes, you may.